
Big Data
Chancen und Gefahren des Datensammelns
Walter Tydecks • Walter Tydecks zu: (Last Update: 20.07.2015)
Einleitung
Mit Big Data sind Datenmengen gemeint, die so groß sind, dass sie nur mithilfe digitaler Datenverarbeitung ausgewertet werden können. In der Regel entstehen sie auch maschinell durch Sensoren oder andere elektronische Aufzeichnungen.
In Unternehmen werden große Datenmengen aus technischen Daten der Produktion, Verkaufszahlen und Marketing-Daten über die Märkte erzeugt, auf denen das Unternehmen aktiv ist. Big Data dient daher vor allem als Mittel, die Verkaufsaktivitäten im Markt besser zu steuern.
In der öffentlichen Diskussion sind dagegen vor allem Big Data gemeint, die durch Protokollierung von elektronischen Medien gewonnen werden, wie Suche im Internet, Telefonieren mit Smartphones, bargeldloses Bezahlen mit Chipkarten, Auswertung von E-Mail-Aktivitäten etc. Hauptvertreter dieser Richtung ist der amerikanische Wissenschaftler Alex Pentland, der führende Positionen in der Entwicklung von Big Data innehat und u.a. auf dem World Economic Forum in Davos aufgetreten ist.
Unterschiedliche Skandale von Google, Facebook und NSA haben Big Data in Verruf gebracht. Mit Big Data droht sowohl eine vollständige Überwachung wie auch eine umfassende Sozialkontrolle, wenn versucht wird, aus den mit Big Data gewonnenen Daten Verhaltensmuster zu erkennen und bereits im Vorfeld präventiv einzugreifen.
Es kommt hinzu, dass Big Data teilweise hervorgegangen ist aus den spieltheoretischen Anwendungen, die für die Finanzwirtschaft in den 1990ern entwickelt wurden und zum Finanz-Crash 2008 mit beigetragen haben. Wird diese Entwicklung weiter zurück verfolgt, dann liegen die Wurzeln in der amerikanischen RAND-Corporation, die nach 1945 gegründet wurde und eine wichtige Rolle im Kalten Krieg spielte.
Schließlich haben sich die Biologie und insbesondere die Evolutionstheorie der Spieltheorie angenähert. Seit Dawkins wird der Evolutions-Prozess in einer ähnlichen Sprache wie die Spieltheorie dargestellt, die Evolution erscheint als das große »Spiel des Lebens«. Biologische Forschung liefert auf ihre Weise Big Data und soll ermöglichen, das Verhalten biologischer Prozesse zu verstehen und vorauszusagen und begründet neue Anwendungsgebiete von Robotern und intelligenten künstlichen Maschinen.
Es ist noch schwer abzuschätzen, wie sich diese Strömungen miteinander verbinden. Die Realität von Google und anderen zeigt, in welche Richtung es geht. Das öffentliche Interesse ist groß, und das wichtigste Buch, das über diese Fragen geschrieben wurde, war 2013 ein Bestseller: Ego: das Spiel des Lebens von Frank Schirrmacher.
Zahlen und Fakten
Alle 1,2 Jahre verdoppelt sich die weltweite Datenmenge. Der Weltumsatz für Big Data (Produkte und Dienstleistungen) betrug 2014 ca. 74 Mrd. Dollar. Das ist entspricht einem Viertel des Volumens der jährlichen Ausgaben für Weltraumfahrt.
Internet-Anwender: 2014 gab es 3 Mrd. Anwender, die Zahl ist seit 1999 stetig linear ansteigend. Der Anteil von Asien beträgt bereits 48,4%. Es gibt ca. 700 Mio Websites, die Zahl stagniert seit 2011 (internetlivestats). Etwa 42% der Internet-Anwender kaufen über Internet ein (statista), der weltweite Umsatz betrug 2013 1,2 Mrd. US-Dollar (statista).
E-Mails: 2014 gab es 2,5 Mrd. E-Mail-User. Geschäftliche Anwender senden täglich 36 E-Mails und empfangen 85. Diese Zahlen werden weiter steigen. Privat werden täglich pro Anwender 88 E-Mails versandt und empfangen. Die privaten E-Mails werden jedoch zunehmend verdrängt von Social Networking (Facebook u.a.), Instant Messaging (whatsapp u.a.), SMS (Quelle: radicati).
Social Networking: 2014 gab es 1,2 Mrd. Anwender mit durchschnittlich jeweils 3 Konten (Quelle: radicati).
Handys: 2013 gab es 4,55 Mrd. Handy-Nutzer, die 6,8 Mrd. Handys besitzen, davon 1,75 Mrd. SmartPhone-Nutzer (Wikipedia, emarketer).
Google Anfragen: 2014 wurden täglich 3,6 Mrd. Suchanfragen bei Google eingegeben (wobei der Marktanteil von Google an allen Suchanfragen 78% beträgt) (internetlivestats).
YouTube: 2014 nutzten monatlich 1 Mrd. Anwender YouTube und betrachteten monatlich über 6 Mrd. Stunden Videos (youtube).
Digitale Werbung: Internet-Firmen finanzieren sich zu einem großen Teil über Werbung. 2013 wurden weltweit 121 Mrd. US-Dollar für digitale Werbung ausgegeben (statista). Zum Vergleich: Der Weltpharmamarkt betrug 2011 821 Mrd. $, der Umsatz für Big Data (Produkte und Dienstleistungen) betrug 2014 weltweit 74 Mrd. $.
Wearable Devices (tragbare Geräte): Zum Beispiel Armbanduhren, Fitnessbänder, intelligente Kleidung, Brillen, Hörgeräte (siehe Wikipedia). Die Entwicklung steht noch ganz am Anfang. 2014 sind weltweit ca. 36.000 Geräte im Einsatz, überwiegend in USA. Sie kommunizieren über SmartPhones und beanspruchen ca. 0,1% des mobilen Datenvolumens (cisco).
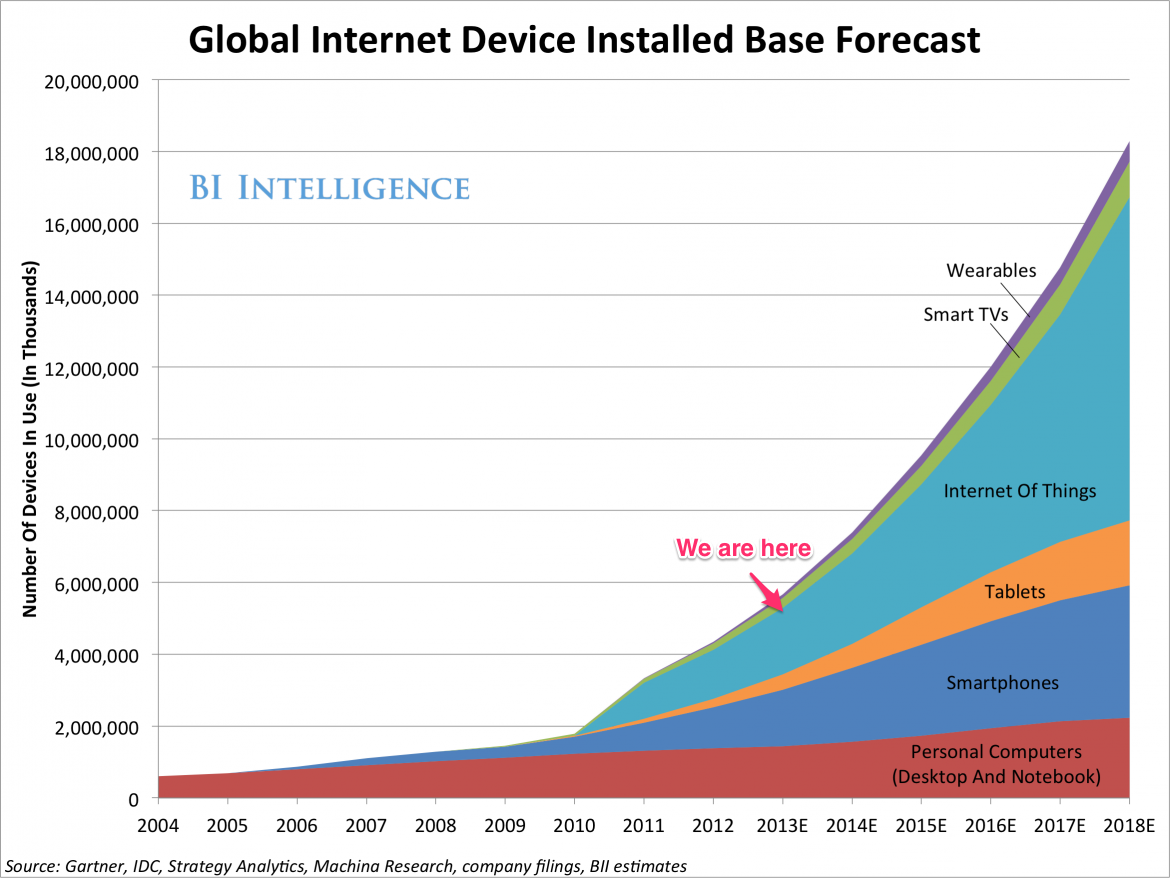
Quelle: Business Insider The Internet of Everything 2014; Link
Internet der Dinge: Schon in wenigen Jahren wird das »Internet der Dinge« die klassischen Geräte wie PC, Notebook und Smartphone überholen. Das sind zum Beispiel Signalanlagen (Thermostate, Rauchmelder), Ampeln, Überwachungsanlagen (Videokameras, Bewegungsmelder), Waschmaschinen die dann waschen wenn Strom günstig ist, Kühlschränke die Leerstand oder Vereisung melden, etc. Die von solchen Geräten erzeugten Daten sprengen alle bisher bekannten Größenordnungen.
Am Beispiel „Big Data auf Rädern”: Sechs Paradigmen
Das Ende des gewohnten Autofahrens ist in Sicht: Für das Jahr 2020 hat Apple die Auslieferung des iCar angekündigt, batterie-getrieben und selbstfahrend, Big Data auf Rädern. Wie findet ein Programm von sich aus den optimalen Weg, ohne dass ein Fahrer am Steuer eingreifen muss? Am Beispiel einer Fahrt von Bensheim nach Heidelberg werden 6 verschiedene Paradigmen erläutert, wie Autofahren aussehen kann und mit welchen Methoden Big Data arbeitet.
(1) Die klassische Mechanik sucht nach einem optimierten Weg, der idealerweise durch eine einzige Kurve dargestellt wird, für die es eine eindeutige mathematische Funktion gibt. Eins der faszinierendsten Beispiele der jüngeren Zeit war die Berechnung der Flugbahn des Raumschiffs Rosetta von der Erde zum Kometen Tschuri, worüber wir in Kürze mehr hören werden. Auf ähnliche Weise kann auch nach dem kürzesten und schnellsten Weg für eine Autofahrt gefragt werden. Hier sind Parameter zu berücksichtigen wie Länge und Qualität der Straßenabschnitte, Verkehrsdichte, Kreuzungen, Baustellen, Ampeln, technische Werte des benutzten Autos, Ermüdungserscheinungen des Fahrers etc. Im Prinzip sollte es möglich sein, aus Parametern dieser Art eindeutig den optimalen Weg zu bestimmen und fortlaufend nachzujustieren.
Das ist die Vorgehensweise der klassischen Naturwissenschaft, die sich bis in den Alltag durchgesetzt hat, wenn nach der optimalen Lösung für ein Problem gesucht wird. In der Regel wird davon ausgegangen, dass es voneinander unabhängige Parameter und unter ihnen einen optimalen Ausgleich gibt, der mithilfe wissenschaftlicher Methoden erarbeitet und aus den jeweiligen Voraussetzungen hergeleitet werden kann.
(2) Völlig anders denkt die Quantenmechanik. Sie sucht nicht nach einer kontinuierlichen Kurve, die vom Start zum Ziel führt, sondern rastert den Bewegungsraum in kleinste Einheiten (Zustände). Das ist im Beispiel einer Fahrt von Bensheim nach Heidelberg die Menge aller Wegkreuzungen einschließlich des Start- und Zielpunktes. Jede Wegkreuzung gilt als ein Zustand des Systems (das ist in diesem Beispiel das fahrende Auto), und es wird für jede Kreuzung gemessen, wie wahrscheinlich es ist, ob, wann, wie lange und wie oft die Bewegungsbahn über diese Kreuzung führt. Weiter wird die Übergangswahrscheinlichkeit gemessen, von einer Kreuzung zu einer anderen zu kommen. Die Fahrt ist an ihr Ziel gekommen, wenn das System sich in dem Zustand 'Zielpunkt' befindet. (Anmerkung: Quantenmechanik ist "nur" Statistik und Wahrscheinlichkeitstheorie. Das sieht im nachhinein sehr einfach aus, doch ist es eine große Kunst, für die jeweilige Aufgabenstellung die geeigneten Basiselemente zu finden. Im Weiteren werden Beispiele folgen, die zeigen, dass in vielen Fällen anfangs ein sehr unübersichtliches Datenmaterial vorliegt, in dem nur sehr schwer Basiszustände zu erkennen sind.)
Jeder einzelne Straßenabschnitt von einer Kreuzung zur nächsten wird danach bewertet, wie lang er ist und mit welcher Geschwindigkeit er durchfahren werden kann, wobei bewusst auf die Frage verzichtet wird, woraus sich die größere oder kleinere Geschwindigkeit erklärt (das könnten Staus, Ampeln, Ortsdurchfahrten etc. sein). Die Quantenmechanik lässt theoretisch auch äußerst unwahrscheinliche Fälle zu, wie z.B. die Möglichkeit, in einem einzigen Schritt mit Überspringen aller dazwischen liegenden Kreuzungen zum Ziel zu tunneln, oder dass ungewöhnliche Bedingungen gegeben sein könnten, unter denen der schnellste Weg von Bensheim über eine entfernte Stadt wie Paris nach Heidelberg führt, oder dass entgegen aller Alltagserfahrung unterwegs Schleifen gefahren werden. Solche Fälle werden nicht wie von der klassischen Mechanik – und dem gesunden Menschenverstand – von vornherein »verboten«, sondern nur mit einer extrem geringen Wahrscheinlichkeit bewertet. Das zu verstehen ist die große und einzige Schwierigkeit und zeigt das Neue der Quantenmechanik: Sie geht nicht von Erklärungen und Gründen aus, und schließt daher nicht alles dasjenige aus, wofür es keine Erklärung gibt (wie z.B. den Fall einer unmittelbaren Bewegung von Bensheim nach Heidelberg), sondern entwirft nur einen abstrakten Lösungsraum, in dem alle Möglichkeiten enthalten sind, auch diejenigen, die aus Sicht der klassischen Mechanik und Alltagserfahrung unerklärlich sind und für sie daher als »unmöglich« gelten.
Mit diesem Ansatz kann schrittweise der wahrscheinlichste Weg vom Start zum Ziel berechnet werden. Kommt es zu Hindernissen (z.B. die Überquerung des Neckars), die nur mit sehr großer Unwahrscheinlichkeit direkt überwunden werden können, wird solange ein Weg um das Hindernis herum gesucht, bis eine Lösung gefunden ist, die hohe Wahrscheinlichkeit aufweist. Im Ergebnis entsteht eine Karte, wie sie z.B. von Google Maps abgerufen werden kann. Das Verfahren entspricht dem von der Informatik entwickelten A*-Algorithmus.

»Illustration der Wegfindung um ein Hindernis mittels A*-Suche. Bekannte Knoten sind hellblau umrandet, abschließend untersuchte Knoten sind ausgefüllt. Die Farbe letzterer markiert dabei die Entfernung zum Ziel; je grüner, desto weniger weit ist dieser vom Ziel entfernt. Zu beobachten ist, dass der A* zuerst in einer geraden Linie in Richtung Ziel strebt, bis er auf das Hindernis stößt. Erreicht er den Zielknoten, erkundet er zuerst noch alternative Knoten in der Open List, bevor er terminiert« Wikipedia, abgerufen 5.2.2015).
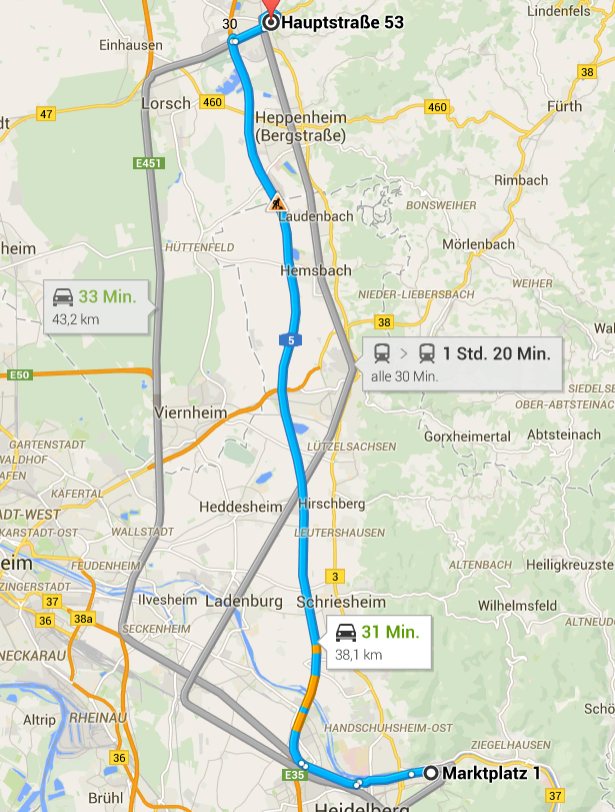
Routenplanung von Bensheim Hauptstraße 53 nach Heidelberg Marktplatz 1 mittels Google Maps, abgerufen 5.2.2015. Eine Fahrt per Rad über die B3 wird auf 1 Std. 43 Min. für 33,6 km geschätzt.
Ein Nachteil dieser Methode ist sicher, dass die Gründe unbekannt bleiben, warum dieser Weg der kürzeste ist. Dafür kann auf lokale Veränderungen leichter reagiert werden. Es ist zwar auch möglich, die Parameter einer Funktion anzupassen, wenn unvorhergesehene Ereignisse eintreten, doch kann das außerordentlich aufwändig werden. Nach diesem Netzwerk-Modell ist dagegen keine Änderung des zugrunde liegenden Algorithmus notwendig, wenn die Nachricht eintrifft, dass sich aus irgendwelchen Gründen die Werte in einem bestimmten Abschnitt verändert haben. Die Routenplanung kann fortlaufend angepasst weden.
(3) Auf diesem Ansatz bauen die Algorithmen von Big Data auf, wurden jedoch seither nochmals durchgreifend geändert. Im Beispiel der Autofahrt wird jetzt nicht mehr gemessen und ausgewertet, wie groß jeweils die Geschwindigkeit auf den einzelnen Abschnitten zwischen den Kreuzungen ist, sondern wie sich der Schwarm der Autofahrer verhält. Wenn die meisten von Bensheim nach Heidelberg die Bergstraßen-Autobahn A5 nutzen, folgen wir ihnen. Wenn aus irgendeinem Grund der Schwarm bei Hemsbach von der Autobahn abbiegt, folgen wir ihm. Hierfür ist nur erforderlich, das End-Ziel der Autofahrer zu kennen und ihr Verhalten zu messen.
Dieser Ansatz kann fortlaufend verbessert werden. So kann anhand der Nummernschilder erkannt werden, wer wahrscheinlich ortskundig ist, um ihr Verhalten höher zu bewerten. Oder es kann ausgewertet werden, wer unsicher ist und über Smartphone jemanden um Hilfe anruft, den Verkehrsfunk abfragt oder sonstige Informationen einholt, um seine Route zu optimieren. Wichtig ist hier, dass wie im vorherigen Beispiel prinzipiell nicht nach den Gründen gefragt wird, warum sich die einzelnen Autofahrer so verhalten, sondern lediglich Durchschnittswerte ihres Verhaltens erhoben werden.
Der Algorithmus kann weiter verbessert werden, wenn untersucht wird, wie oft und bei welchen Verhaltensmustern sich die Anpassung an das Schwarmverhalten gelohnt hat und ob es Regelmäßigkeiten gibt, wann es besser ist, sich vom Schwarm zu trennen und Schleichwege zu nutzen, und sich aktiv dem Sog zu entziehen, der jeden dazu treibt, sich dem Schwarm anzuschließen.
Damit ist das Prinzip von Big Data erklärt. Es beruht ausschließlich auf der statistischen Auswertung von menschlichem Verhalten und kann immer genauer voraussagen, wie ein Mensch sich im weiteren verhalten wird, wenn sein bisheriger Weg bekannt ist.
(4) Bisher ging es um die Planung der Fahrt zu einem anderen Ort. Was geschieht, wenn die Reise begonnen wurde und der Fahrer sich im Gewühl des Schwarms bewegt? Auch hier wird das Verhalten des Reisenden beobachtet. Jeder fühlt sich zwar in seinem Fahrzeug frei, aber bei statistischer Auswertung großer Mengen von Reisenden zeigt sich, dass es bestimmte Verhaltensmuster gibt, die von der Spieltheorie untersucht werden.
(a) Falken kämpfen und versuchen jeden Autofahrer vor ihnen zu überholen. Obwohl der Zeitgewinn nicht groß ist und ein solches Verhalten viel Kraft kostet, ist für sie das Autofahren ein Spiel, sich gegen andere durchzusetzen. (b) Tauben kämpfen nie, halten bei jeder Baustelle die geforderte Geschwindigkeit ein und wagen sich kaum aus dem Windschatten eines LKWs hervor. Sie werden von jedem Falken verdrängt, kommen aber entspannter an ihr Ziel und sind möglicherweise den Falken überlegen, wenn die Fahrt nicht nur nach dem Parameter der Geschwindigkeit, sondern auch unter Berücksichtigung des Energieverbrauchs optimiert wird. (c) Rächer (retaliator) sind Tauben, die sich jedoch rächen, wenn sie angegriffen werden. Haben sie das Gefühl, dass sie von jemand bedrängt werden, dann wagen sie sich hervor, bremsen einen Drängler aus und lassen sich auf einen zähen Kampf ein, an dessen Ende sie beweisen wollen, wer der Stärkere ist. (d) Ein »Bully« greift solange alle an, bis er selbst angegriffen wird und sich dann sofort zurückzieht und aufgibt. (e) Ein »prober-Retaliator« (versuchsweise Rächer) ist jemand, der normalerweise nur angreift, wenn er angegriffen wird, aber bisweilen austestet, ob sich ein Wechsel zum Falken lohnt.
Eine Population von Tauben kann von Falken und Bullies unterwandert werden. Falken können von Tauben und Bullies unterwandert werden. Bullies können von Falken unterwandert werden. Daher ist wahrscheinlich, dass sich im Ergebnis eine Mischung von Rächern und versuchsweise-Rächern ergibt.
Im Ganzen kann gefragt werden, welche Verteilung unterschiedlicher Spieler-Typen am effektivsten ist. Ein gewisser Anteil von Falken macht Druck und erhöht das Tempo, während umgekehrt ein Anteil von Tauben erforderlich ist, um Ordnung und Gleichmaß aufrecht zu erhalten. Ohne Tauben würde es ständig zu Unfällen kommen, wodurch die Geschwindigkeit im Ganzen verlangsamt würde, ohne Falken droht der Verkehrsfluß einzuschlafen.
Diese Art der Spieltheorie hat sich nach 1945 im Kalten Krieg durchgesetzt und prägt seither nicht nur das Autofahren, sondern alle gesellschaftlichen Verhaltensweisen. Die Theorie der Evolutionär Stabilen Strategie entstand 1973 und wurde von Dawkins popularisiert, dem hier die Darstellung folgt (siehe Das egoistische Gen, Kapitel 5 über Aggression). Schirrmacher beklagt zurecht, dass seither Egoismus und Aggression zu den gesellschaftlich bestimmenden und anerkannten Werten geworden sind.
Angewandt auf selbstfahrende Autos bedeutet das, dass mit ihnen das heute gewohnte aggressive Fahrverhalten verloren gehen könnte. Welcher Falke will freiwillig auf die Erfahrung verzichten, den Autoverkehr dominieren zu können? Dagegen kann zum einen eingewandt werden, dass die heutige Verkehrsdichte ein solches Verhalten ohnehin kaum mehr möglich macht, und zum anderen könnten mit Aufpreis Fahrzeuge erworben werden, die dank überlegener Technik wendiger und mobiler sind, und dadurch weiterhin ihren Besitzern erlauben, auch bei Einhaltung aller Sicherheitsregeln andere Autos zu überholen.
(5) In Kalifornien hat sich längst eine Gegenbewegung durchgesetzt. Ist es wirklich sinnvoll, sich in dieser Art vom Straßenverkehr aufreiben zu lassen, und sollte nicht stattdessen auch das Autofahren wie jede andere Gelegenheit genutzt werden, nach bisher unbekannten Geschäftsmodellen Ausschau zu halten? »Der Mensch nach Hoffmann ist ständig im Radarmodus. Er weiß, dass seine Lebensform fragil ist, und wenn er nicht wie ein Börsentrader ständig bereit ist, Chancen zu nutzen, riskiert er „eine riesige Explosion in der Zukunft”« (Schirrmacher, S. 249f).
Reid Hoffman, dessen Karriere von Fujitsu und Apple zur Gründung von Unternehmen wie PayPal und LinkedIn führt, empfiehlt jedem, sein eigener Start-Up-Unternehmer zu werden. Wer von Bensheim nach Heidelberg fährt, sollte sich überlegen, welche Möglichkeiten Geld zu verdienen er hier entdecken kann. So könnten mit einer App andere Reisende nicht nur vor Staus gewarnt, sondern auch informiert werden, welche nahegelegenen Reiseziele andere auf dieser Strecke besichtigt und für interessant befunden haben. Oder wer will, schlägt in einem der vielen Partnerportale nach, ob zufälligerweise interessante Menschen nach einer Mitfahrgelegenheit suchen und die es lohnt, kennenzulernen. Ähnlich wie bei der Einrichtung neuartiger Cafés ist es zu einem Ideenwettbewerb gekommen nach dem Motto, auf der Fahrt zu einem anderen Ort neue Wege zu gehen. Mit Big Data kann ermittelt werden, welcher Geschäftsideen solcher Art erfolgversprechend sind. Google, Apple, Facebook und andere präsentieren ständig neue Ideen in dieser Richtung, und im Ergebnis wird in naher Zukunft das klassische Autofahren völlig abgeschafft und an Big-Data-basierte Anwendungen übergeben werden.
(6) Bedeutet diese Art von Ideenwettbewerb aber nicht wiederum Stress und führt zu einem Verdrängungswettbewerb, an dessen Ende nur sehr wenige mit den besten und erfolgreichsten Geschäftsideen sehr reich sein werden und die Fähigkeiten der Vielen entwertet sind? Etwas unvermittelt sei daher abschließend als Gegenpol die klassische Ethik von Aristoteles genannt. Er untersuchte Fähigkeiten, die sich Big Data entziehen. Im Beispiel einer Reise könnten das Besonnenheit, Aufmerksamkeit und Freude an der Mobilität sein, was in Deutschland klassisch als Lust am Wandern bezeichnet wurde. Wer sich wie der Taugenichts von Eichendorff die Geige nimmt und auf den Weg macht, wird sich an keine der bisher genannten fünf Lösungswege halten.
Die Anfänge von Big Data im Kalten Krieg
Big Data geht zurück auf die Anfänge der Radar- und Computertechnologie aus der Zeit des 2. Weltkriegs und des Kalten Krieges nach 1945. Frank Schirrmacher vertritt in Ego – das Spiel des Lebens die These, dass sich aus diesem Kontext erklärt, warum Big Data bis heute überwiegend mit Aggression und Paranoia zu tun hat. Der Mensch sieht sich mit unübersehbar großen Datenmengen konfrontiert und will aus ihnen erklären, welche Absichten ein potentieller Gegner hat und wie darauf zu antworten ist.
Seit 1935 wurde vor allem in Deutschland, England, Russland und USA intensiv die Radartechnologie erforscht und entwickelt. England teilte seine Kenntnisse mit den Commonwealth-Ländern und den USA. Das MIT Radiation Laboratory bei Boston bestand 1940-1945. Von hier kam der Rechtsanwalt Horace Rowan Gaither (1909-1961), der in den 1950ern Chef der RAND Corporation und der Ford Foundation war. Schirrmacher beginnt sein Buch mit den Erfahrungen von Soldaten, die bei der ermüdenden Arbeit an Radar-Geräten zur Luftraum-Überwachung in eine Art Trance fielen. Ähnliches Datenmaterial gibt es inzwischen in den verschiedensten Bereichen, seien es die Aufnahmen der Teilchenbeschleuniger oder die Ticker von Aktienkursverläufen.
Mit der Radartechnologie können Erscheinungen sichtbar gemacht werden, die sich der gewöhnlichen menschlichen Wahrnehmungsfähigkeit entziehen. Mit ihnen soll es möglich sein, frühzeitig Entwicklungen zu erkennen und zu durchschauen, die im Verborgenen ablaufen. Weil sich diese Bilder der üblichen Erfahrung entziehen, ist es kaum möglich, sich in ihnen zu orientieren. Das sei an einem aktuellen Beispiel der Wetterbeobachtung gezeigt:
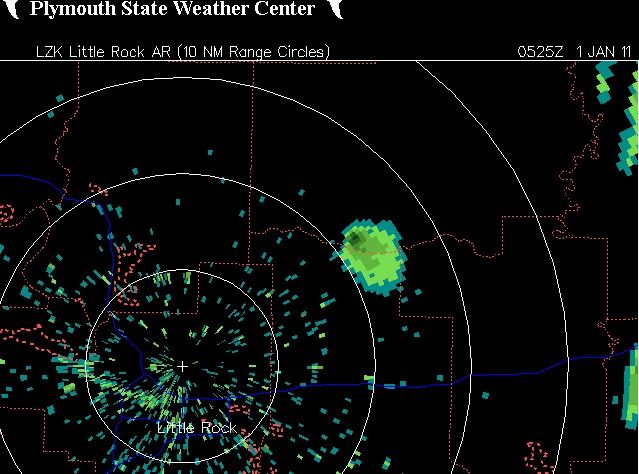
»Doppler-Radarbild über Beebe, Arkansas, was ein großes Radarzeichen wiedergibt. Ist es ein Vogelschwarm, eine Meteorexplosion oder etwas anderes?« (Joe Quinn und Niall Bradley in einem Beitrag über planetare Katastrophen, Bildnachweis: Link)
Wer über große Zeiträume hinweg mit dem Gefühl konkreter Bedrohung Daten solcher Art auszuwerten hat, um zu erkennen, ob sich in ihnen eine akute Bedrohung ablesen lässt wie z.B. ein gegnerischer Raketenangriff oder ein aus dem Kosmos kommender Meteorit, der wird wie von Schirrmacher beschrieben in eine Art Trance verfallen. Daraus entstanden sowohl Projekte, wie Menschen in einer solchen Arbeitssituation psychologisch betreut werden können, als auch die Aufgabe, die Überwachung und Auswertung der Datenmengen an automatisierte Systeme zu übertragen.
Das bedeutet aber, dass es gelingen muss, für Computer Programme zu entwickeln, die aus unübersichtlichen Datenmengen Gefährdungen herauslesen und melden können. In der Konsequenz führte das zu einem neuen Paradigma, wie naturwissenschaftliche Daten zu interpretieren sind: Ein Haufen unverständlicher, chaotisch wirkender Punkte kann möglicherweise entziffert werden als Folge von Spielzügen gegnerischer Parteien. Wer zum Beispiel eine Folge von Spielzügen eines Go- oder eines Schach-Spieles als Muster wählt, kann daraus die verallgemeinerte Idee entwickeln, dass eventuell jeder Punktfolge ein Spiel mit Spielregeln, Spielern und deren Strategien zugrunde liegt, welche es zu durchschauen gilt.
Das ist ein Paradigmen-Wandel gegenüber der klassischen Vorstellung. Nach der klassischen Vorstellung wurde angenommen, dass sich große Datenmengen zu einer zusammenhängenden Strömung oder zu einem Feld zusammenfügen lassen und die ihnen zugrunde liegenden mathematischen Parameter und Feldgleichungen zu erarbeiten sind. Um dafür einen Ansatz zu finden, wurden einige Grundannahmen gesetzt: Es wurde angenommen, dass diesen Systemen Prinzipien der Ökonomie und der Harmonie zugrunde liegen, nach denen die Natur den kürzesten Weg mit dem geringsten Kraftaufwand geht und nach Gleichgewichten strebt.
Der spieltheoretische Ansatz geht dagegen von der Grundannahme aus, dass sich in den Punktmengen Spielzüge erkennen lassen, mit denen eine Seite die andere überwältigen und letztlich auslöschen will. Damit wurden die Prinzipien des aufklärerischen Denkens völlig umgekehrt. An die Stelle der aufklärerischen Sprache mit ihrem Anspruch nach Klarheit und Verständlichkeit ist eine Sprache mit einem ironischen, militaristischen Ton getreten. Schirrmacher nennt als Beispiele Ausdrücke wie »skalpieren«, »killen«, »ausblasen«, »den Gegenspieler einfrieren bis zur Handlungsunfähigkeit«, »niedermähen«, »Massaker« (Schirrmacher, S. 87f). Diese Sprachweise hat sich im Umgang der führenden Politiker untereinander durchgesetzt, wie die von Whistleblowern weitergegebenen Dokumente zeigen, und ist auf breiter Front in den Medien und in der Alltagssprache angekommen.
Dieser Paradigmenwechsel wurde jedoch nie öffentlich diskutiert oder bewusst vollzogen, sondern ergab sich aus der Erfahrung der gesellschaftlichen Katastrophen des 20. Jahrhunderts. Mit ihnen war die Aufklärung in Frage gestellt. Wenn früher Leibniz vorgeworfen worden war, dass das Erdbeben von Lissabon mit seinen zahlreichen Toten seine Philosophie widerlegt, wonach wir in der bestmöglichen aller Welten leben, hatte sich diese Skepsis um 1945 vollständig durchgesetzt. Ihre gesellschaftlichen, philosophischen und religiösen Konsequenzen wurden jedoch nicht offen diskutiert. Stattdessen setzten sich unterschiedliche Formen eines neuen Aberglaubens wie die Angst vor Ufos durch und ein Klima der allseitigen und allgegenwärtigen Verdächtigung, welches seither alle Anwendungen von Big Data bis zu den heute bekannten Methoden von NSA (National Security Agency) beeinflusst. Das Buch von Schirrmacher war ein erster Versuch, die Dimension dieser Veränderung bewusst zu machen.
Was im 2. Weltkrieg entstanden war, wurde im Kalten Krieg nahezu unbegrenzt fortgeführt. Der Kalte Krieg begann, als mit der Zündung der ersten sowjetischen Atombombe am 29.8.1949 das amerikanische Atomwaffen-Monopol durchbrochen war. Es folgten unmittelbar im Oktober 1949 die Ausrufung der Volksrepublik China und im Juni 1950 der Korea-Krieg, dessen Brutalität heute weitgehend vergessen ist, und der erst im Juli 1953 mit einem Waffenstillstand endete. In den USA herrschte große Angst vor einem sowjetischen Angriff mit teilweise paranoiden Zügen.
Statt einer gründlichen Untersuchung der veränderten Weltlage mit all ihren Auswirkungen auf das Denken und den Glauben der Menschen entstand die Spieltheorie, die von Anfang an einen besonderen Status eines Religionsersatzes und einer Geheimwissenschaft bekam. Ihre Ergebnisse wurden lange Zeit wie eine Geheimwaffe verborgen gehalten und wie ein Staatsgeheimnis betrachtet, mit deren Hilfe im Kalten Krieg der Gegner auf mentaler Ebene dominiert werden sollte. Die Erosion der Demokratie und der offenen Gesellschaft begann, und die Politik verlagerte sich von parlamentarischen Debatten und Entscheidungen zu Ausschuss-Sitzungen unter Ausschluß der Öffentlichkeit.
Die Spieltheorie wurde maßgeblich an der RAND Corporation entwickelt. Ihr Ursprung liegt in einer Veröffentlichung 1944 von John von Neumann und Oskar Morgenstern. Bereits am 1.10.1945 wurde 2 Monate nach den Atombombenabwürfen in Hiroshima und Nagasaki das Projekt RAND gegründet, aus dem am 14.5.1948 die RAND Corporation hervorging. Eine ihrer Aufgaben war zu analysieren, wie es zu den Trance-Zuständen bei der Luftraum-Beobachtung kommen konnte. Die Spieltheorie wurde lange wie ein militärisches Geheimnis gehütet und kaum öffentlich gelehrt. Die Liste einiger Namen von Mitarbeitern bei RAND zeigt deren Stellenwert für Politik und Wirtschaft in den USA: Bei RAND wirkten neben John Nash (* 1928, Nash-Gleichgewicht 1950) auch Robert Aumann (* 1930 in Frankfurt, 1938 geflohen, Theorie wiederholter Spiele, versucht den Krieg berechenbar zu machen, spieltheoretische Talmud-Exegese, heute radikale Positionen zur Palästina-Frage), Kenneth Arrow (* 1928, Marktgleichgewichte, asymmetrische Informationsökonomie u.a.), Paul Baran (1926-2011, Computernetzwerke, Vorläufer des Internet), Hubert Dreyfus (* 1929, 1965 bei RAND, philosophische Einschätzung der Künstlichen Intelligenz), Fukuyama (* 1952, 1979 bei RAND), Horace Rowan Gaither (1909-1961, Gründer und in den 1950ern Vorsitzender von RAND), Karen Elliott House (* 1947, Journalistin, Wall Street Journal, seit 2009 Vorsitzende von RAND und im Vorstand des Council on Foreign Relations), Herman Kahn (1922-1983), Henry Kissinger, Harry Markowitz (* 1927, Portfolio-Theorie), Margaret Mead (1948-50 bei RAND über russische Kultur), John Milnor (* 1931, 1951 bei RAND, kombinatorische Spieltheorie, Differentialtopologie), Condoleeza Rice, Donald Rumsfeld, Paul Samuelson.
Biologie: Wie löst die Natur Big Data Aufgaben
– Algorithmen und Replikationen in der Evolutionstheorie
Die Verbindung von Evolutionstheorie und Statistik geht auf die 1920er zurück. Der englische Mathematiker Ronald Aylmer Fisher (1890-1962, 1911 Gründer der Eugenik Gesellschaft, obwohl konservativ und kirchlich mit Haldane und Wright Gründer der Poputionsgenetik) war einer der wichtigsten Wegbereiter statistischer Methoden und des Design neuartiger, statistisch auswertbarer Experimente. 1930 erschien seine bahnbrechende Arbeit zur sexuellen Selektion. Er ist für Dawkins der bedeutendste Nachfolger von Darwin.
Was anfangs nur wie ein neues Anwendungsfeld der Statistik ausgesehen hatte, bekam mit der Entdeckung des molekularen Aufbaus der DNS (Desoxyribonukleinsäure) von 1953 eine völlig neue Wende: Der Träger des Erbguts sieht aus wie ein komplizierter Lochstreifen oder eine verdrillte Spielwalze für einen Leierkasten. Innerhalb der Natur kommt es zu Replikationen von Erbgut. Die Natur verhält sich wie ein Computer. Algorithmen werden nicht mehr nur vom Menschen entworfen, sondern die Programmierer können in der Natur deren Algorithmen lesen und von ihnen lernen und sie bewusst in künstlichen Umgebungen einsetzen. Im Ergebnis können sowohl informationsverarbeitende Organismen aus der Natur wie eine Black Box in künstliche Maschinen als Module eingebaut werden, wie auch Anwendungen entworfen werden, die die Abläufe solcher Organismen nachbilden.
Es war nur eine Frage der Zeit, bis diese beiden Richtungen zusammenkamen. In den 1960ern wurden von den Schüler Fishers weitere Experimente über das Verhalten unterschiedlicher Populationen bezüglich Ernährung und Fortpflanzung durchgeführt. Die ersten mathematischen Darstellungen gehen auf den britischen Biologen William Hamilton (1936-2000) zurück. Er stellte 1964 eine mathematische Regel auf, in welchem Maß Tiere ihre Verwandten solange unterstützen, wie der mit dem Verwandtschaftsgrad gewichtete Nutzen größer ist als die Kosten. Der Verwandtschaftsgrad entspricht nicht unbedingt den unter Menschen üblichen Vererbungslehren, sondern muss empirisch beobachtet werden. Mit diesem Ansatz konnte das ungewöhnliche Verhalten von Hautflüglern (Bienen, Ameisen, Wespen) erklärt und auf ungleiche Verteilungen von Chromosomensätzen zurückgeführt werden (Haplodiploidie). Was bisher als moralisches Gebot und als gesellschaftlich verbindliche Vererbungsregel galt, wurde mathematisch formuliert und empirisch an der Struktur des Erbguts und der Regeln ihrer Replikation nachgewiesen.
Auf ähnliche Weisen wurden Hypothesen über das sexuelle Verhalten von Männchen und Weibchen aufgestellt und bei verschiedenen Tierarten untersucht. Das betrifft Fragen wie Monogamie oder Polygamie, Haremsgesellschaften, gemeinsame Aufzucht des Nachwuchses durch Männchen und Weibchen, asymmetrische Geschlechtsverhältnisse wie bei den Bienen mit Königinnen, Arbeitsbienen und Drohnen, die Bedeutung von Homosexualität für eine Art oder die Frage, ob unterschiedliche sexuelle Verhaltensweisen innerhalb einer Art gleichzeitig bestehen und diese möglicherweise fördern können. Im Ergebnis sollte die Frage beantwortet werden, ob bestimmte sexuelle Verhaltensweisen das Überleben einer Art fördern oder gefährden, und ob sie genetisch bedingt sind.
Der Ansatz der Spieltheorie ist damit genau umgedreht worden: Es wird nicht in einem mathematischen Modell ein bestimmtes Verhalten durchgerechnet und anschließend im wirklichen Leben angewendet, sondern es wird bei existierenden Organismen untersucht, welche Verhaltensweisen dort beobachtet werden können und sich gemäß den Regeln der Evolution durchgesetzt haben.
Doch gibt es gegenüber der klassischen Spieltheorie wesentliche Unterschiede, die von den Vertretern der Spieltheorie gern heruntergespielt werden: In der Spieltheorie ist die völlige Auslöschung des Gegners möglich. Der Pokerspieler spielt solange, bis seine Gegner alles Geld verloren haben. In der Biologie werden jedoch Verhältnisse betrachtet, bei denen die Spieler voneinander abhängig sind und miteinander wechselwirken. Wird ein Spieler völlig ausgelöscht, ist damit auch für den anderen Spieler die Lebensgrundlage entzogen. Das wurde anfangs an den elementaren Beispielen von Ernährung und Fortpflanzung untersucht: Wenn die Jäger ihre Beute vollständig aufgefressen haben, verhungern sie. Wenn es keine Weibchen oder keine Männchen mehr gibt oder die Fortpflanzung zugunsten anderer Aktivitäten völlig aufgegeben wird, stirbt die Art aus.
Die Populationsgenetik betrachtet auf zahlreichen Ebenen Wechselwirkungen:
(1) Einbettung der DNS in die Lebensvorgänge innerhalb einer Zelle, und bei mehrzelligen Lebewesen Verhältnis von Genotyp und Phänotyp. Die Gene können sich zwar replizieren, aber sie brauchen einen Wirt, über den sie weitergetragen werden. Kommt es zu Entwicklungen, durch die der Wirt völlig ausgelöscht wird, kann auch das Gen nicht überleben.
(2) Gegenseitige Abhängigkeit von Genen innerhalb eines Biotops. Lebewesen können nicht allein überleben, sondern nur in Wechselwirkung mit anderen. »Man schätzt, dass in und auf dem Menschen ca. 1015 Mikroorganismen leben und somit die Anzahl menschlicher Zellen um den Faktor 10 übertreffen« (Blickpunkt Q1 2011/2012, S. 39, Veröffentlichung von BRAIN Zwingenberg). Die Kommunikation einer solchen Menge von Organismen kann nur mit Methoden von Big Data ausgewertet werden. Siehe hierzu die Metagenomik.
(3) Umwelteinflüsse.
(4) Möglicherweise verborgene Parameter. Die Verhaltensweisen werden statistisch ausgewertet. Möglicherweise gibt es Anomalien. Daraus kann gelernt werden, ob es in der Natur bestimmte Regelmäßigkeiten bei Verhaltensweisen gibt, von denen die Menschen lernen können. Hier wird die Natur nicht nur wie in der Bionik nachgebaut, sondern von den Mustern ihrer Wechselprozesse gelernt.
Im Grunde steht die Forschung noch am Anfang. Wenn dennoch weitreichende Thesen wie das »egoistische Gen« vertreten werden, kann das bestenfalls als eine mögliche Vision die Forschung anregen, jedoch auch die Offenheit für neue Entdeckungen hemmen.
So gibt die Evolutionstheorie Big Data zwei Aufgabenfelder: (1) Auswertung des Verhaltens großer Populationen, (2) Auswertung der Gene, ihrer Sequenzen (DNA-Sequenzanalyse) und ihrer Bündelung in Metagenomen. Derzeit werden fortlaufend Gendatenbanken aufgebaut und umfassen bereits mehrere Millionen Gene.
Wie weit die Forschung gediehen ist, zeigt eine 2012 bekannt gemachte umfassende Computersimulation, mit der alle Abläufe des einfachen Bakteriums Mycoplasma genitalium in einem Programm nachgebaut wurden. Die Vorgänge in der Zelle wurden in 28 Submodule zerlegt. Das Programm enthält alle 525 Gene des Bakeriums und über 1.900 beobachtete Parameter. Im Ergebnis soll es möglich sein, mit dem Programm Veränderungen des Erbguts zu simulieren und die daraus resultierenden Veränderungen des Phänotyps zu berechnen.
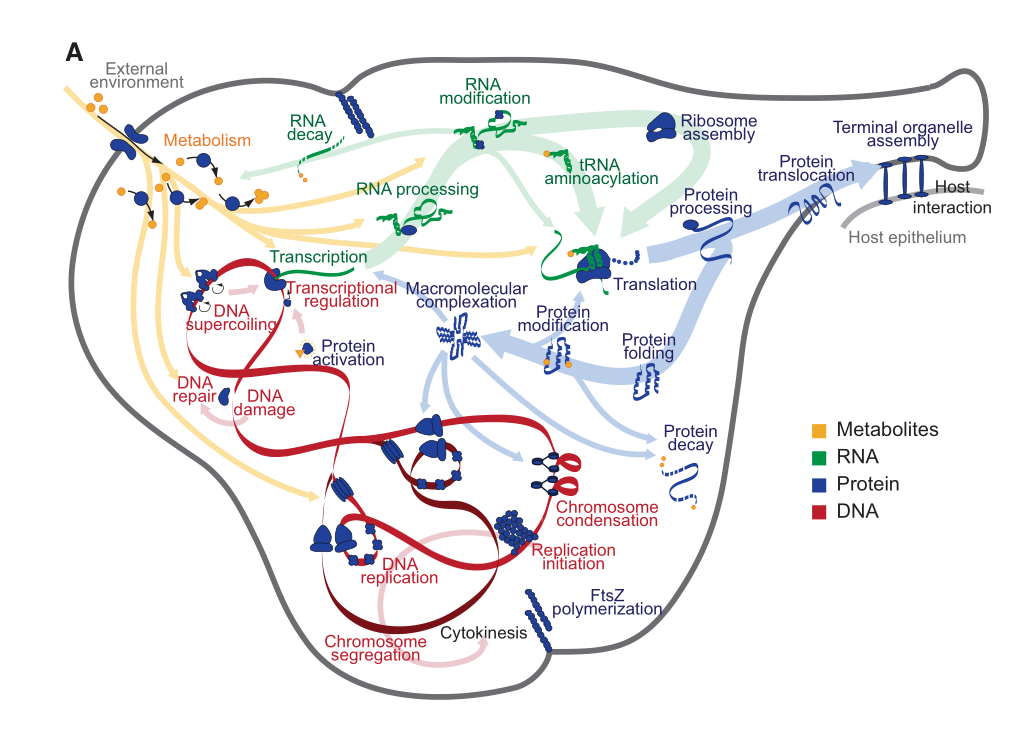
Mycoplasma genitalium Whole-Cell Model
Das Modell enthält 28 miteinander vernetzte Submodule, die die Vorgänge innerhalb der Zelle und mit der Umgebung ausführen. Quelle: sciencedirect.com
Auch in der Evolutionstheorie scheint die rasante Entwicklung der Forschung die gesellschaftliche, philosophische und religiöse Diskussion zu überholen. So wie die Bedeutung der Spieltheorie nie in ihrer ganzen Reichweite öffentlich diskutiert und bewertet wurde, ist die besondere Bedeutung der Populationsgenetik noch nicht ausreichend ins Bewusstsein gekommen. Es wird auch nicht öffentlich diskutiert, welcher Wandel von der Spieltheorie zur Populationsgenetik vollzogen wird und welche Tragweite er hat. Um nur ein Beispiel zu nennen, wie tief Fragen dieser Art bis in religiöse Grundüberzeugungen reichen: Während monotheistische Religionen akzeptieren oder sogar fördern, dass bestimmte von Gott auserwählte Völker andere Völker völlig auslöschen, wie bei der Landnahme der Hebräer nach der Flucht aus Ägypten oder bei der Verdrängung der Indianer in Nordamerika, fordern andere am antiken Denken orientierte Richtungen umgekehrt die Erhaltung einer möglichst großen Biodiversität, da sie davon ausgehen, dass von der Natur alle lebenden Organismen mit einem Erbgut ausgestattet wurden, dass auf Dauer für die Erhaltung des Lebens notwendig sein kann.
So bleibt derzeit für Big Data in der Evolutionstheorie ein vorwiegend pragmatischer Ansatz, mithilfe fortlaufend verbesserter algorithmischer Methoden der Bioinformatik die Ergebnisse der Populationsgentik zu ermitteln und so weit wie möglich kommerziell zu nutzen. (Dies Thema soll im Juli 2015 bei der geplanten Veranstaltung zur Enzym-Technik weiter ausgeführt werden.)
Top Ingenieure und Average (Durchschnitts) Ingenieure
Die Vielfalt der biologischen Prozesse entfernt sich weit von den überlieferten mechanischen Prozessen. Die Zelle ist nicht bürokratisch organisiert, sondern lebt von einer vielfältigen und komplexen Wechselwirkung ihrer Teilprozesse. Wenn auf solche Weise durch Beboachtung biologischer Prozesse gelernt werden kann, stellt sich die Frage, ob auch gesellschaftliche Prozesse auf ähnliche Weise untersucht werden können, um zu erkennen, welche Verhaltensweisen am erfolgreichsten sind.
In dieser Richtung war eine 1999 veröffentlichte Studie bahnbrechend, in deren Geist seither zahlreiche weitere Forschungen in Big Data erfolgen, die sich weit von einfachen utilitaristischen oder liberalen Ansätzen entfernen. Auch wenn dies Thema nicht unmittelbar zu Big Data gehört, soll es vorgestellt werden, um besser zu verstehen, welche Richtung die Big Data Forschung seither einschlägt.
Firmen wie Bell Lab wollten wissen, warum sie trotz Rekrutierung ihrer Mitarbeiter von den weltbesten Universitäten mit den erfolgreichsten Abschlüssen trotzdem nicht die Star Performer bekamen, die sie erwartet hatten. Was unterscheidet einen Star Performer vom Average Performer? Es sind offenbar nicht die Eliteuniversität und der blendende Abschluss. Über tausend Ingenieure von Bell, HewlettPackard und 3M beteiligten sich an einer Langzeitstudie, die 1985 begonnen wurde. Das Ergebnis wurde 1999 veröffentlicht.
Mit dieser Studie wurden bewusst nicht bestimmte Inhalte untersucht. Es wurde nicht gefragt, auf welchen Gebieten Star Ingenieure besonders erfolgreich sind. Sondern entsprechend einer behavioristischen Grundposition wurde ausschließlich das Verhalten der Ingenieure betrachtet. Wie verhalten sich die Star Performer? Kelley fasst das Ergebnis in 9 Strategien zusammen.
(1) Blaizing trails. Ein guter Ingenieur versteht sein Berufsfeld, hält sich an die Vorgaben und erfüllt optimal das, was von ihm erwartet wird. Er entwickelt Initiativen, diese Aufgabe besser zu erfüllen, aber er kommt geht nicht über die Aufgabenstellung hinaus. Der Star Performer erkennt die Schwächen der Stellenbeschreibung und konzentriert sich genau darauf. Er löst Aufgaben, auf die er stößt, und für die es noch keine Vorgaben gibt.
(2) Knowing who knows. Star Performer finden heraus, wen sie fragen müssen. Das können auch Menschen sein, die in anderen Abteilungen arbeiten, fern von ihrem Fach, aber mit den richtigen Fragen und dem weiterführenden Verständnis.
(3) Proactive self-management. Average Performer konzentrieren sich auf Aufgaben wie Zeit- und Projektmangement. Wen sein Vorgesetzter auf ein solches Seminar schickt, der sollte entweder daraus den Schluss ziehen, wie wenig ihm zugetraut wird, oder sein Vorgesetzter verliert bei ihm jede Autorität für Vorschläge dieser Art. Statt in Seminaren über Zeit- und Projektmanagement Zeit zu verlieren, erkennt er, wo im aktuell bearbeiteten Projekt die verborgenen Schwierigkeiten liegen und bereitet sich darauf intensiv vor.
(4) Getting the big picture. Der Star Performer blickt über den Tellerrand und vermag seine Aufgabe auch von außen zu sehen.
(5) The right kind of followership. Average Performer glauben ihrem Chef zeigen zu müssen, dass sie seine Vorgaben verstehen und vorbildlich umzusetzen vermögen. Star Performer verhalten sich wie eine höhere Art von persönlichen Assistenten: Sie erkennen vorausschauend, wo ihr Chef unsicher ist oder welche Aufgaben er liegen lässt und kommen mit Vorschlägen, die Aufgaben betreffen, für die es noch keine Vorgaben gibt. »Daran hatte ich noch gar nicht gedacht.«
(6) Teamwork as joint ownership of a project. Average Performer erwarten von einem Team, dass alle gut zusammenarbeiten und voneinander profitieren. Star Performer erkennen die Schwierigkeiten im Team und beginnen selbständig denen zu helfen, die nicht weiter kommen und dadurch die Arbeit aufhalten. Damit ist nicht gemeint, dass es ihnen an Fähigkeiten mangelt, sondern dass sie stärker als andere an Stellen stehen, an denen sich strukturelle Probleme des Teams besonders deutlich zeigen. Sie leiden stärker unter übergeordneten Problemen. Star Performer erkennen das und suchen nach einer Lösung.
(7) Small-I leadership. Average Performer sind überzeugt, dass ohne sie nichts läuft und übernehmen am liebsten alles selbst, damit es vorangeht. Star Performer nehmen sich zurück, hören zu und helfen mehr durch die richtigen Rückfragen als durch Zeigen, wie etwas besser zu machen ist.
(8) Street smarts. Average Performer versuchen, die Mikropolitik und die verborgenen Machtstrukturen zu verstehen und über sie möglichst schnell eine bestimmende und unabkömmliche Rolle zu erreichen. Star Performer erkennen die Lücken und setzen dort an, wo etwas fehlt. Sie wollen nicht in erster Linie verstehen, wie eine Organisation tickt und sie sich dort einbringen können, sondern woran sie stockt.
(9) Show and tell. Der Average Performer bemüht sich, seine Leistung möglichst vielen Vorgesetzten zu präsentieren und auf seine Fähigkeiten aufmerksam zu machen. Der Star Performer trägt sein Wissen und seine Anliegen in kleinen Kreisen vor, die meist aus unterschiedlichen Hierarchie-Ebenen stammen, aus verschiedenen Richtungen gemischt sind und ihn mit überraschenden Fragen konfrontieren.
Wird ein Unternehmen erfolgreicher, wenn dort viele Mitarbeiter mit solchen Fähigkeiten beschäftigt sind, oder müssen sie eine Ausnahme bleiben und können ihre Fähigkeiten nur entfalten, wenn es um sie herum ausreichend viele Kollegen mit traditionellem Arbeitsethos und Führungsverhalten gibt? Zeigt sich hier ein Paradigmenwechsel im Arbeitsleben, oder handelt es sich nur um einzelne "Paradiesvögel", die die notwendigen Ideen bringen? In diesen Fragen herrscht heute noch viel Skepsis, und es ist zu erwarten, dass noch einige Studien erforderlich sind, um den Wertewandel vollziehen zu können.
Big Data als Sozialwissenschaft und Sozialkontrolle
Diese Studie ist sehr populär geworden, und nach ihrer Methode wollen auch die Big Data Forscher vorgehen. Wenn sie menschliche Kommunikation untersuchen, geht es ihnen nicht in erster Linie um die Inhalte, über die gesprochen wird, sondern um wiedererkennbare Muster in der Kommunikation. Mit Big Data wird nicht eine bestimmte Frage beantwortet, sondern nur das Verhalten gemessen, um daraus Voraussagen über die erwarteten Handlungen abzuleiten. Big Data hat den Anspruch, das gesellschaftliche Leben mit der gleichen Neutralität zu untersuchen wie ein Physiker die Bewegung eines fallenden Steins oder die Aufenthalts-Wahrscheinlichkeiten eines Photons misst und mathematisch beschreibt. Daher möchte Alex Pentland dieser Richtung den Namen Soziale Physik geben, wie er sein 2014 veröffentlichtes Buch über Big Data genannt hat.
Was ist heute bereits möglich?
Arbeitsablauf im Büro: Alle Mitarbeiter in einem Call Center bekommen eine Art Smartphone umgehängt, mit dem nicht nur ihre gesprochenen Worte aufgezeichnet werden, sondern auch ihre Körperbewegungen. Der Tonfall und die Tonlage zeigt, wann ein Sprecher sich unter Stress fühlt und wann er sicher ist. Die Aufzeichnungen im Call Center haben ergeben, dass bereits nach wenigen Sekunden erkennbar ist, ob die Anfrage erfolgreich beantwortet werden kann. Läuft es schief, kann das Gespräch sofort auf einen anderen Mitarbeiter umgestellt werden. Das Call Center kann versuchen, nur solche Mitarbeiter einzustellen, deren Stimmprobe dem im jeweiligen Call Center erfolgreichsten Muster am nächsten kommt. Nach den optimistischen Ergebnissen der Big Data Forscher kann mit solchen Methoden die sales performance um 20 % oder mehr gesteigert werden. (Diese Beispiele nennt Mark Buchanan, S. 3, Buchanan, geboren 1961, ist Physiker und Journalist bei Nature, arbeitet bei Booz Allen Hamilton Inc., das ist das Unternehmen, bei dem auch Snowden seine entscheidenden Karriereschritte absolvierte).
Im Call Center wurde die Pausenregelung geändert. Hatte anfangs der einfachste Controlling-Ansatz dominiert, möglichst wenige Pause zu gewähren und möglichst zu vermeiden, dass mehrere Mitarbeiter gleichzeitig Pause machen, wurde das dank Big Data Ergebnissen korrigiert: Die Effektivität konnte deutlich erhöht werden, wenn umgekehrt regelmäßig gruppenweise Pausen stattfinden. Das ergab intensive Gespräche, einen regelmäßigen Austausch über schwierige Kundenanfragen, und hat im Ergebnis die Produktivität erhöht (Pentland, S. 93-95). – Umgekehrt hat sich in Börsen gezeigt, dass dort die Wertpapierhändler viel zu dicht aufeinander saßen. Das hat die Konzentration auf selbständiges Denken abgelenkt und einen Herdentrieb gefördert, der im Ganzen unproduktiv war. Die Leistung konnte wesentlich gesteigert werden, als den einzelnen Händlern mehr Raum für Selbständigkeit gegeben wurde (Pentland, S. 30f). – Von Google wird berichtet, dass dort die Mitarbeiter über einen bestimmten Zeitanteil völlig frei verfügen können, und in der Regel in diesen Phasen die kreativsten Ideen entstehen.
Sensoren und Mikrofone in der Kleidung oder am Körper können auswerten, wer wie häufig zu wem geht und wer wie häufig mit wem spricht. Wieder geht es nicht um die Inhalte, über die gesprochen wird, und es soll auch nicht um Spionage gehen, sondern in anonymisierter Form um ein Soziogramm. Was jeder vermutete, ließ sich auf diese Weise empirisch nachweisen: In erfolgreichen Gruppen dominiert niemand das Gespräch. Kurze und wechselnde Redebeiträge, alle kommen zu Wort. Aufeinander Hören, wechselseitige Bestätigung und nur selten unterbricht jemand wen anders. Körpersprache wird wahrgenommen und verstanden. Es gibt nur kurzfristige Ausnahmen von dieser Regel in Phasen extremen zeitlichen Drucks oder hoher Emotionalität (Pentland, S. 88-90). – Es können bisher verborgene »informelle« Gruppen erkannt werden, und es lassen sich Mitarbeiter identifizieren, über die ungewöhnlich viele Kontakte laufen und die in Stress und auf Dauer in Burnout zu geraten drohen und Verstärkung brauchen. – Firmen können mithilfe von Sensoren erkennen, wie sich neue Mitarbeiter einfinden (wie schnell bauen sie Kontakte auf, haben sie oft Leerlaufzeiten etc.).
Bei einem Gehaltsgespräch kann schon nach 5 Minuten mit 87% Wahrscheinlichkeit an äußeren Symptomen gemessen werden, wie es verlaufen wird, auch wenn das reale Gespräch häufig länger als eine Stunde dauert. Diese Art von Auswertung lässt sich beliebig ausdehnen. An Videos frisch verheirateter Paare soll durch Analyse der Gesichtsmimik abgelesen werden, ob die Ehe erfolgreich verlaufen wird (Buchanan, S. 5f).
Die Vertreter der Sozialen Physik sprechen vom Übergang eines neutralen Data Mining, (»sinngemäß „in einem Datenberg nach wertvollem Wissen suchen”«; Wikipedia) zum Reality Mining. Damit ist gemeint, dass die Daten nicht erst statistisch erhoben und dann aus der Statistik ausgewertet, sondern direkt mit Sensoren aus der Wirklichkeit abgelesen werden können.
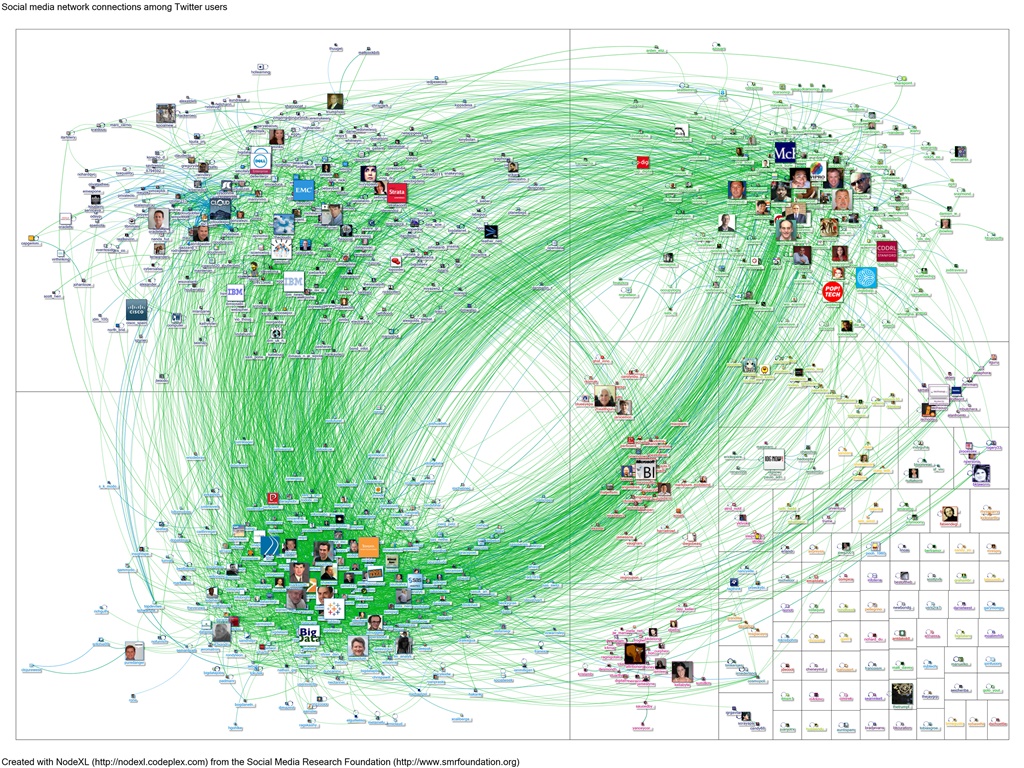
Twitter-Netzwerk
Big Data überwacht Big Data: Netzwerk aller Twitter-Anwender, die am 27. Februar 2012 nach dem Stichwort Big Data gesucht haben. Grüne Linien zeigen Followers, blaue Linien Antworten oder Kommentare. Quelle: Britannica Blog
Belohnungssysteme In den Labors von Social Physics wird experimentiert, ob nicht die heute bekannten Belohnungssysteme völlig antiquiert sind. Hier geht es nicht um die häufig genannten Anstupser (Nudges), sondern um Ideen, wie zum Beispiel die Installation von Solaranlagen dadurch zu fördern, dass nicht der Bauherr, sondern seine Nachbarn eine Prämie erhalten. Das erhöht den sozialen Druck und wird auf Dauer den Innovatoren am meisten nutzen, wenn nach und nach ihre Nachbarn ihnen folgen (Pentland, S. 73). Ähnlich kann bei Organisationen nicht nur ein erfolgreicher Neueinsteiger belohnt werden, sondern auch derjenige, der ihn zum Beitritt bewogen hat.
Das sind Beispiele für weiterführende Ideen, die den herkömmlich mit Big Data verbundenen Ansatz völlig verändern können. Dann bedeutet Big Data nicht mehr, dass ein übermächtiger Datentopf aufgebaut wird, aus dem heraus sich alles lückenlos planen lässt, sondern dass die lokale Eigeninitiatve gefördert wird. Solche Ideen vertritt der in der Schweiz lehrende Komplexitätsforscher Dirk Helbing, siehe das vor wenigen Tagen ausgestrahlte Interview in der Fernsehreihe Sternstunde Philosophie (YouTube). Er hat seine Forschungen mit Studien über Verkehrsströme begonnen. Bis heute ist es selbst größten Rechnern nicht möglich, aus der Vielzahl von Verkehrsdaten eine optimale Ampelschaltung auszurechnen und zu steuern. Stattdessen sollten die Autofahrer Informationen bekommen, sich dem Verkehrsfluss optimal anzupassen und zu einer Selbstorganisation des Verkehrssystems beizutragen.
E-Mail Auswertungen Geradezu klassisch mutet im Vergleich hierzu der Algorithmus an, mit dem das Unternehmen Cataphora für Gerichtsprozesse den kompletten elektronischen Schriftverkehr der Beteiligten auswertet. Schirrmacher zitiert deren Vorstandsvorsitzende Elizabeth Charnock (* 1967). Sie veröffentlichte 2010 einige Ergebnisse in E-Habits: What You Must Do to Optimize Your Professional Digital Presence.
»Nachdem wir eine Weile gearbeitet hatten, begannen wir zu verstehen, dass wir mehr über unsere Ziele wussten – wirklich mehr – als ihre Ehepartner und engsten Freunde. Vielleicht mehr, als sie selbst von sich wussten. ... Wir konnten die logische Konsistenz ihrer Ansichten untersuchen und feststellen, ob sie die gleichen Ansichten gegenüber verschiedenen Menschen äußerten.« (zitiert bei Schirrmacher, S. 264)
Auch hier liegen die Ergebnisse nicht einfach in den kommunizierten Inhalten, sondern nach welchen Mustern miteinander gesprochen und aneinander geschrieben wird. Wer antwortet wie schnell und wie ausführlich wem und informiert anschließend Dritte. Wann brechen Kontakte ab, und wann häufen sie sich. Charnock analysiert bis ins Detail die schizophren anmutenden Unterschiede zwischen Selbstbild und tatsächlichem Verhalten. Oft haben Schreiber von E-Mails eine ganz andere Vorstellung über ihr Kommunikationsverhalten, als es sich in den Daten zeigt.
»Die Cataphora-Software kann beispielsweise erfassen, welche Schriftfarben Mitarbeiter in Emails benutzen, wie sie Ausrufezeichen setzen oder mit Hilfe von anderen Satzzeichen Flüche formulieren, wie sie ihre Emails beenden und ob sie 'bitte' häufiger als üblich verwenden. Denn das scheinbar arglose Wörtchen 'bitte' kann bereits eine Menge über einen Angestellten verraten. ... (Ein anderes System) hält in regelmäßigen Abständen den Bildschirminhalt der laufenden Rechner fest und notiert, wann Dateien auf einen USB-Stick verschoben werden. Hält sich ein Mitarbeiter zu lange auf bestimmten Webseiten auf, gibt die Software Warnmeldungen an die Vorgesetzten ab. Wieviel Zeit für das Schreiben von Emails draufgeht, wer die meisten Email-Anhänge versendet. ... Kommt die Software zu dem Schluss, dass eine Formulierung Kollegen unabsichtlich verärgern könnte, blendet sie eine Warnmeldung ein« (Heise).
Schirrmacher kommentiert:
»Diese Algorithmen verstehen natürlich nicht, was jemand 'meint', wenn er Worte wie 'traurig', 'schlecht', 'ärgerlich' benutzt. [...] Er übersetzt Kommunikation in ein ökonomisches Modell. Unter der Oberfläche der Worte arbeitet eine Ökonomie des Gebens und Nehmens wie ein Motor, 'danke' und 'bitte'« (S. 264).
Produkteinführung Auf ähnliche Weise wie die zwischenmenschliche Kommunikation kann auch der Umgang von Menschen mit Produkten gemessen und ausgewertet werden. Produkten werden Sensoren eingebaut um zu erkennen, ob es den Anwendern gelingt, sie zu nutzen.
Datenschutz und Spionage Die Chancen von Big Data sind offensichtlich. Krankheiten und Epidemien können frühzeitig erkannt werden. Häufig wird die Anwendung Google Flu Trends genannt: Wenn auffallend viele Menschen in Google nach Informationen im Umfeld von Grippe fragen, kommt es zu einer Grippe-Welle (siehe z.B. den Artikel in FAZ vom 15.11.2014). Alleinstehende alte Menschen können mit Sensoren versorgt werden, die sich melden, wenn bestimmte Routinen verlassen werden. Im Prinzip kann jeder jederzeit an eine medizinische Rundum-Überwachung angeschlossen werden.
Alle Befürworter der Sozialen Physik räumen jedoch ein, dass viele Anwender sich durch diese Methoden kontrolliert fühlen und eine Art Taylorismus in intellektuellen Arbeitsabläufen droht. Sie halten die Methoden von Big Data auf Dauer nur für verwirklichbar, wenn die Sicherheitsbedenken der Anwender berücksichtigt werden. Pentland tritt für einen New Deal of Data ein. Heute haben die Internet-Firmen noch einen Vorlauf, den sie so weit und so lange wie möglich ausnutzen wollen: Die meisten Nutzer sind sich nicht bewusst, wie wertvoll ihre Daten sind, und dass sie auf ähnliche Weise Eigentumsrechte darauf beanspruchen können wie auf jede andere Art von Privatbesitz. Daher werden Ideen für eine neue Rechtssprechung entwickelt, um auf die zu erwartenden Proteste antworten zu können. Die Internet-Firmen versuchen allerdings, den Zeitvorsprung zu nutzen und Fakten zu schaffen, die sich nicht mehr ändern lassen, und werden hierbei von politischen und militärischen Interessen unterstützt.
Nicht erst die Enthüllungen über NSA durch Snowden haben gezeigt, wie diese Art der Beobachtung zu Spionage- und Kontrollzwecken eingesetzt wird. Schirrmacher zitiert den Sozialwissenschaftler Christakis (* 1962, Leiter des Human Nature Lab an der Yale University), der in erstaunlicher Offenheit schreibt:
»Wenn man einen Sozialwissenschaftler vor 20 Jahren gefragt hätte, hätte er gesagt: 'Es wäre unglaublich, wenn wir einen mikroskopisch kleinen Black-Hawk-Hubschrauber haben könnten, der ständig über Ihnen kreist und alles beobachten würde: wo Sie sind, mit wem Sie reden, was Sie kaufen, was Sie denken, und der das alles ununterbrochen in Echtzeit macht, gleichzeitig für Millionen von Menschen'. Und genau das ist es, was wir jetzt bekommen.« (Nicholas Christakis Link, zitiert S. 191)
Für ihn war die Biologie die große Hoffnung im 20. Jahrhundert, für das 21. Jahrhundert sieht er sie in der Sozialwissenschaft. Es kommen drei Trends zusammen: Zusammenwachsen von Biologie und Sozialwissenschaft, Big Data, soziale Experimente ganz neuen Ausmaßes. Er arbeitet in vergleichbarer Weise wie Pentland am MIT bei Boston:
»The type of experiments you can do has increased dramatically, and their cost has fallen significantly. For example, in my lab, we create virtual laboratories online, where we recruit volunteers to participate in our experiments from around the world. Sometimes we pay them small amounts, for instance, by using Amazon Mechanical Turk. We can do experiments where we drop people into networks with different structures that we experimentally manipulate, and randomly assign them to live in different kinds of worlds, and then see how these people behave. For example, we can study what happens when they're randomly assigned to a world in which the network has one mathematical structure, or, instead, randomly assigned to live in a world where the network has a different mathematical structure.« (Nicholas Christakis edge.org).
Eine Welt ohne Geheimnis Philosophisch liegt diesem Ansatz eine bestimmte Philosophie des Geistes zugrunde, die auf den britischen Philosophen und Wittgenstein-Schüler Gilbert Ryle (1900-1976) und den Behaviorismus zurückgeht. In dieser Tradition werden alle Äußerungen des Geistes als »elektronischer Text« verstanden, so erstmals Shoshana Zuboff (* 1951, emeritierte Ökonomie-Professorin in Harvard, heute jedoch kritisch zu Google, so in der FAZ vom 30.4.2014). Das besagt, dass der Geist an der Menge seiner Äußerungen gemessen werden kann und keine verborgenen Seiten enthält, die bis in die Spiritualität reichen.
Geheimnisse gibt es nicht, aber sehr wohl Geschäftsgeheimnisse. So sehr Google und andere für Transparenz eintreten, behalten sie ihre eigenen Algorithmen geheim. »Sie sind wie die Priester, die eifersüchtig über die Deutung des Wortes Gottes wachen« (Schirrmacher, S. 260).
Was Big Data nicht kann
Big Data stößt an zwei Grenzen:
Big Data liefert keine Beweise und ist daher letztlich nicht überprüfbar.
Big Data kennt keinen freien, spielerischen Umgang mit seinen Daten.
Es gibt Beispiele für mathematische Sätze wie das Vierfarben-Problem, bei denen aufgrund der großen Datenfülle herkömmliche mathematische Beweise nicht möglich waren. In solchen Fällen wird versucht, Programme zu schreiben und mit ihnen alle Fälle durchrechnen zu lassen. Der Aussagewert ist umstritten, denn es kann nicht mit Sicherheit überprüft werden, ob die Programme versteckte Fehler enthalten und daher zu falschen Ergebnissen kommen.
Diese Schwierigkeit erhöht sich, wenn in neuronalen Netzen oder mit Einsatz lebendiger Systeme als Module innerhalb einer Anwendung nicht einmal mehr Algorithmen vollständig entworfen und vorgegeben werden, sondern stattdessen auf die »Intelligenz« von Systemen vertraut wird, deren Vorgehensweisen und Prinzipien nicht verstanden und unbekannt sind.
Zum anderen gibt der Mensch mit Big Data seine spezifische Fähigkeit der Intuition, Einfühlung und des spielerischen Umgangs an Mechanismen ab. Es hat auch etwas Verräterisches, wenn von »Spieltheorie« und dem »Spiel des Lebens« gesprochen wird. Jeder, der sich näher damit beschäftigt, wird schnell enttäuscht werden und nicht das wiederfinden, was er unter Spiel versteht.
Ähnlich ging es bereits Friedrich Schiller. Als er seinen Gedanken begründen wollte, »der Mensch spielt nur, wo er in voller Bedeutung des Wortes Mensch ist, und er ist nur da ganz Mensch, wo er spielt«, sah er sich gezwungen, dies von Beispielen aggressiver Spiele zu unterscheiden. Er dachte an »Brot und Spiele« der Römer, »wenn das römische Volk an dem Todeskampf eines erlegten Gladiators oder seines libyschen Gegners sich labt«, und setzte dagegen die doppelte Forderung: »Der Mensch soll mit der Schönheit nur spielen, und er soll nur mit der Schönheit spielen« (Schiller, Über die ästhetische Erziehung des Menschen, 15. Brief).
Es ist sicherlich möglich, in den Algorithmen von Big Data Schönheitsgesetze wie den Goldenen Schnitt oder die Kontrapunktik einzubauen, aber der freie Umgang mit den Dingen und anderen Lebewesen lässt sich nicht planen. Der französische Philosoph Deleuze nannte dies das »nomadische Denken«.
Designer bewegen sich an der Grenze. Sie kennen die Gesetze, wie Menschen in ihrem Denken und Verhalten beeinflusst und manipuliert werden können, aber sie müssen darüber hinaus Ideen haben, wie etwas von einer ungewohnten Seite gesehen werden kann. Zum Schluss sei daher als Anregung ein Designer-Plakat zum Thema Big Data angeführt.

Mediendesign: Big Data – Small Pictures
»Die Finanzkrise und ihre globalen Auswirkungen haben weltweit eine tiefe Vertrauenskrise hervorgerufen. Die Wissensvermittlung und die Informationsverarbeitung durchleben einen immensen Wandel, der sich auch in der Arbeit des Grafikdesigners niederschlägt. Komplexe Sachverhalte müssen zugänglich und begreifbar gemacht werden, was nur mehr über ihre Visualisierung möglich scheint. Dank Edward Snowden wissen wir inzwischen, dass Big Data auch eine Bedrohung für die Demokratie und die Souveränität von Staaten sowie für die individuelle Freiheit sein kann.. Die Aufgabe eines Designers ist die fundierte Auseinandersetzung mit diesen vielschichtigen Informationen und deren Transformation. Wie aber gehen wir mit den komplexen Inhalten um und welches sind die Kriterien für eine zugängliche Infografik?« Nicolas Bourquin
Anhang: Datenvisualisierung
Big Data ist mit seinen Methoden der Datenvisualisierung bereits dabei, neue Möglichkeiten für die Bildende Kunst zu eröffnen. Ein Beispiel sind kolorierte Wetteraufnahmen. Andere Stichworte sind Infosthetics, Visual Computing, Design Patterns.


Hurrikan Katrina über New Orleans 2005, Tropischer Storm Sonamu 2013
Bildnachweis: firstpulseprojects.net, firstpulseprojects.net
Literaturhinweise
Ken Binmore: Spieltheorie, Stuttgart 2013
Ken Binmore: In einer gerechten Welt gibt es keine Vorgesetzten, Gespräch mit "The European" am 3.6.2013; Link
Bitkom: Markt und Statistik; Link
Susan Blackmore: Die Macht der Meme, Heidelberg u.a. 2000
Danah Boyd: Privacy and Publicity in the Context of Big Data, WWW. Raleigh, North Carolina, 29. April 2010; Link
Mark Buchanan: The Science of Subtle Signals
in: strategy+business magazine (published by Booz Allen Hamilton) Reprint 07307 2007; Link
Corinna Budras: Google weiß, wo die Grippe lauert, in: FAZ vom 15.11.2014
Nicholas Christakis: A new kind of social science for the 21st century
in: Gespräch mit "Edge" am 21. August 2012; Link
Markus Covert u.a.: A Whole-Cell Computational Model Predicts Phenotype from Genotype
in: Cell, Volume 150, Issue 2, 20 Juli 2012, S. 389-401; Link
Wen Dong, Alex Pentland: A Network Analysis of Road Traffic with Vehicle Tracking Data
in: AAAI Spring Symposium on Human Behavior Modeling. Palo Alto, California, USA, 2009; Link
Simon Frost und Henrik Mortsiefer: Big Data auf Rädern, in: Zeit-online 6.1.2015; Link
Antti Hautamäki: Social Physics studies idea flow by big data
A critique of Alex Pentland's new book, 2014; Link
Internet Live Stats: Live und Trends Statistics; Link
Robert Kelley: How to be a star engineer
in: IEEE Spectrum Oktober 1999, S. 51-58; Link
Jaron Lanier: Gadget, Berlin 2012
Alex Pentland: Social Physics, New York 2014
Radicati Group: Email Statistics Report, 2014-2018; Link
Frank Schirrmacher: Ego – das Spiel des Lebens, München 2013
World Economic Forum 2011: Personal Data: The Emergence of a New Asset Class; Link
Shoshana Zuboff: Die Google-Gefahr, Schürfrechte am Leben; FAZ 30.4.2014
Bildnachweis: Schlagwortwolke zum Thema Big Data aus olap.com
{kind=link}
Ihr Kommentar
Falls Sie Stellung nehmen, etwas ergänzen oder korrigieren möchten, können sie das hier gerne tun. Wir freuen uns über Ihre Nachricht.